Understanding Naive Bayes in Machine Learning
What is Naive Bayes?
Naive Bayes is not just another classification algorithm; it’s an algorithm that has stood the test of time. Rooted in probability theory, Naive Bayes provides quick and straightforward solutions for complex datasets. It’s like the Swiss Army knife in a data scientist’s toolkit—simple yet powerful.
Importance in Machine Learning
Why should you care about Naive Bayes? Well, in the fast-paced world of machine learning, where deep learning and neural networks are stealing the show, Naive Bayes offers a compelling alternative. It’s particularly effective for text classification problems, from spam detection to sentiment analysis.
Historical Background
Before diving into the technicalities, let’s take a quick history lesson. The Naive Bayes algorithm owes its foundation to Reverend Thomas Bayes, an 18th-century statistician who laid down the Bayes theorem. This theorem serves as the backbone of the Naive Bayes algorithm.

The Bayes Theorem
Basic Formula
At its core, Naive Bayes relies on Bayes’ theorem, which is expressed as
.
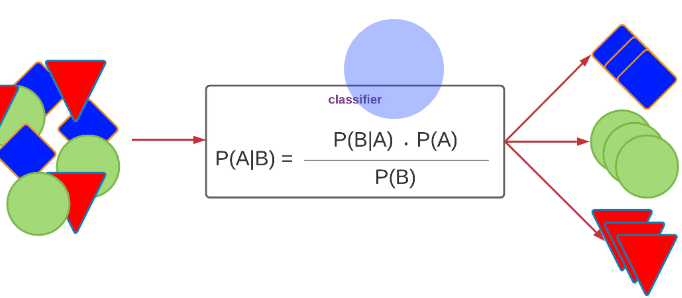
This formula helps us calculate the probability of a hypothesis � based on the prior knowledge �.
Real-world Applications
You’d be surprised how often you use Bayes’ theorem in daily life. Ever judged the likelihood of it raining based on dark clouds? That’s Bayes’ theorem in action. From healthcare diagnostics to stock market predictions, this theorem is a cornerstone in various fields.
Types of Naive Bayes Algorithms
Gaussian
Imagine you’re working with a dataset where the features are continuous. Gaussian Naive Bayes comes to the rescue. It assumes that the continuous values associated with each class are normally distributed.
Multinomial
Text classification problems? Multinomial Naive Bayes is your best bet. It’s widely used in natural language processing tasks where the data are typically represented as word frequency vectors.
Bernoulli
For binary feature problems, Bernoulli Naive Bayes is the algorithm of choice. It’s effective for text classification tasks where binary term occurrence features are used.
How Naive Bayes Works
Feature Independence
Here’s where the “naive” in Naive Bayes comes into play. The algorithm assumes that the features are independent of each other. While this may not hold true in real-world scenarios, the algorithm still performs remarkably well.
Calculating Probabilities
Naive Bayes calculates the probability of each class and the conditional probability of each class given each input value. These probabilities are then used to make predictions.
Advantages of Naive Bayes
Why choose Naive Bayes? First, it’s simple to implement. Second, it’s highly scalable, requiring a number of parameters linear to the number of variables in a learning problem.
Limitations and Challenges
No algorithm is perfect. Naive Bayes is no exception. Its assumption of independent features is its Achilles’ heel. However, in practice, this is often overlooked due to its strong performance on various problems.
Use Cases : Understanding Naive Bayes in Machine Learning
Text Classification
Let’s say you’re building a news aggregator. You could use Naive Bayes to categorize news articles into topics like sports, politics, and technology.
Sentiment Analysis
Ever wondered how companies know what customers are saying about them online? Naive Bayes is often used to analyze customer reviews and tweets to determine public opinion.
Spam Filtering
If you’re tired of spam emails, you can thank Naive Bayes for clearing up your inbox. It’s one of the algorithms that email services use to keep spam at bay.
Implementation Steps : Understanding Naive Bayes in Machine Learning
Data Preparation
Before you jump into coding, your data needs to be in tip-top shape. This involves handling missing values, converting categorical variables into numerical ones, and splitting the dataset into training and testing sets.
Model Training
Using libraries like scikit-learn, you can train a Naive Bayes model with just a few lines of code. The algorithm then learns from the training data.
Evaluation
After training, it’s crucial to evaluate the model using metrics like accuracy, precision, and recall to ensure it meets performance standards.
Popular Libraries for Naive Bayes
Scikit-learn and NLTK are popular Python libraries for implementing Naive Bayes. They offer pre-built methods and classes that make the implementation a breeze.
Comparing Naive Bayes with Other Algorithms
When compared to algorithms like SVM and Random Forest, Naive Bayes holds its ground, especially in text classification problems. It’s often faster and requires less training data.
Optimizing Naive Bayes
Fine-tuning a Naive Bayes model involves techniques like feature selection and parameter tuning. Libraries like scikit-learn offer hyperparameter tuning methods that can help improve the model’s performance.
Future of Naive Bayes
As machine learning evolves, Naive Bayes continues to find new applications and improvements, from real-time predictions to integration with deep learning models.
Conclusion
In the ever-growing field of machine learning, Naive Bayes stands as a testament to the power of simplicity. Its ease of implementation, scalability, and wide range of applications make it a valuable tool for any data scientist.
FAQs
- What is Naive Bayes used for?
- Naive Bayes is primarily used for classification problems, including but not limited to text classification and sentiment analysis. The next Question
- How does Naive Bayes differ from other algorithms?
- Naive Bayes is simpler and often faster, particularly when it comes to text classification problems.
- Is Naive Bayes suitable for large datasets?
- Yes, Naive Bayes is highly scalable and can handle large datasets efficiently.
- What are the limitations of Naive Bayes?
- The main limitation is the assumption of independent features, which may not always hold true.
- How can I optimize a Naive Bayes algorithm?
- Feature selection and hyperparameter tuning are common methods for optimizing Naive Bayes.
If you want to learn more about statistical analysis, including central tendency measures, check out our comprehensive statistical course. Our course provides a hands-on learning experience that covers all the essential statistical concepts and tools, empowering you to analyze complex data with confidence. With practical examples and interactive exercises, you’ll gain the skills you need to succeed in your statistical analysis endeavors. Enroll now and take your statistical knowledge to the next level!
If you’re looking to jumpstart your career as a data analyst, consider enrolling in our comprehensive Data Analyst Bootcamp with Internship program. Our program provides you with the skills and experience necessary to succeed in today’s data-driven world. You’ll learn the fundamentals of statistical analysis, as well as how to use tools such as SQL, Python, Excel, and PowerBI to analyze and visualize data designed by Mohammad Arshad, 18 years of Data Science & AI Experience. But that’s not all – our program also includes a 3-month internship with us where you can showcase your Capstone Project.
Are you passionate about AI and Data Science? Looking to connect with like-minded individuals, learn new concepts, and apply them in real-world situations? Join our growing AI community today! We provide a platform where you can engage in insightful discussions, share resources, collaborate on projects, and learn from experts in the field.
Don’t miss out on this opportunity to broaden your horizons and sharpen your skills. Visit https://nas.io/artificialintelligence and be part of our AI community. We can’t wait to see what you’ll bring to the table. Let’s shape the future of AI together!

We’re a group of volunteers and starting a new scheme in our community. Your site provided us with valuable information to work on. You’ve done an impressive job and our whole community will be grateful to you.