In the ever-evolving world of machine learning and artificial intelligence, one architecture has stood out for its groundbreaking approach—The Transformer. If you’ve ever wondered how Google Translate has become so accurate or why chatbots seem almost human-like in their responses, you’ve got the Transformer architecture to thank for that. Attention is all you Need paper has explained this well.
Importance of Understanding Attention Mechanisms
Understanding the intricacies of attention mechanisms is not just for tech geeks or AI researchers. It’s for anyone who wants to grasp how significant strides in natural language processing (NLP) and machine translation have been made. So, why should you care? Because attention mechanisms are revolutionizing the way machines understand and generate human language.
The Genesis of Attention Mechanisms
Traditional Models: RNNs and CNNs
Before the advent of attention mechanisms, Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs) were the go-to architectures for NLP tasks. While they had their moments of glory, they also had limitations, such as the vanishing gradient problem in RNNs and the lack of sequential understanding in CNNs.
The Shift Toward Attention
That’s when attention mechanisms came into the picture, offering a more efficient way to handle sequence-to-sequence tasks. Imagine trying to translate a sentence from English to French. Instead of processing each word independently, attention allows the model to focus on specific parts of the input sentence, much like how humans pay attention to different parts of a visual scene.
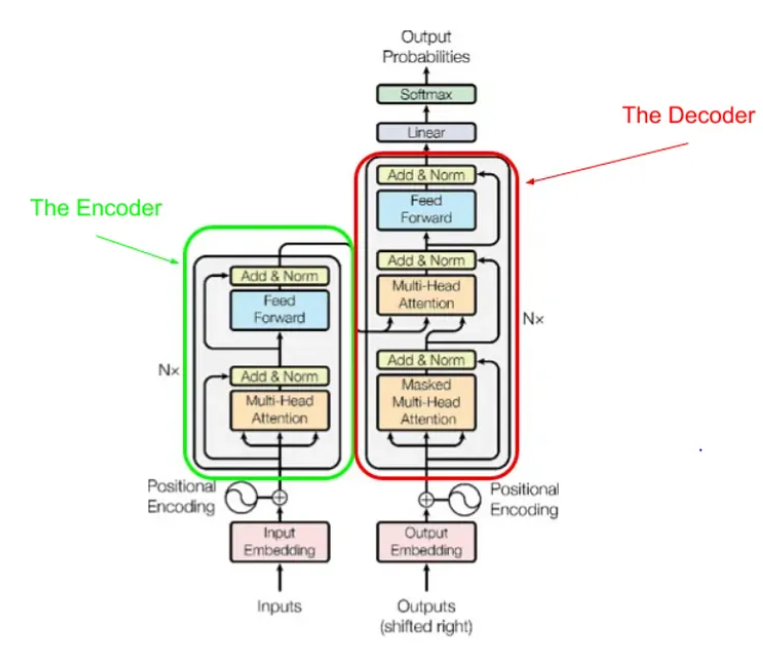
What is the Transformer Architecture?
Basic Definition
The Transformer architecture is like a high-tech factory for data. Raw materials (your input data) go in one end, and a finished product (your output data) comes out the other. It’s designed to handle tasks like language translation and text summarization.
Components
Encoder
The encoder acts as the initial quality check in this data factory. It examines the raw materials (your sentence or paragraph) and prepares a detailed report (context or memory) for the next stage. For example, if the input is the sentence “I love ice cream,” the encoder processes each word and its relationship to the others, creating a ‘context’ that captures the sentiment and subject of the sentence.
Decoder
The decoder is the craftsman of this factory. It takes the ‘context’ and crafts the final product. In a translation task, for instance, it would take the ‘context’ from the sentence “I love ice cream” and generate its equivalent in another language, like “J’adore la glace” in French.
Diving Deep into the Encoder: Self-Attention Mechanism
Query, Key, Value Vectors
In self-attention, each word in the input sentence is transformed into Query, Key, and Value vectors. These vectors are computed in a way that allows the model to focus on specific parts of the input. For example, in the sentence “The cat sat on the mat,” the word “cat” would have a Query vector querying the other words, Key vectors that serve as keys to unlock those queries, and Value vectors that contain the actual content to focus on.
Scaled Dot-Product Attention
The attention scores are calculated using the dot product of the Query and Key vectors, then scaled down. This allows the model to give different levels of attention to different words. For instance, if “cat” is the Query and “mat” is the Key, the dot product helps calculate how much the word “cat” should focus on the word “mat” when forming the output.
Feed-Forward Neural Networks
These are standard neural networks that follow the attention layers. They help in further transforming the attention output. After determining that “cat” should focus a lot on “mat,” a feed-forward neural network might help decide the type of relationship between “cat” and “mat,” like whether the cat is on or under the mat.

Understanding the Decoder
Masked Self-Attention
Masked self-attention ensures that the prediction for a particular word doesn’t depend on future words. It’s like reading a book but not skipping ahead. For example, if the decoder is generating the sentence “She will go,” it won’t use “go” to predict “will” because, in natural reading, “go” comes after “will.”
Encoder-Decoder Attention
This layer helps the decoder focus on relevant parts of the input sentence. In translating “I love ice cream” to French, this layer helps the decoder focus on “love” when translating “J’adore” in “J’adore la glace.”
Key Concepts Explained
Positional Encoding
Transformers lack a built-in sense of sequence. Positional encodings are added to give the model some semblance of order. For example, in the sentence “I love ice cream,” positional encoding helps the model distinguish the order of words, so it doesn’t mistake it for “Ice cream loves I.”
Multi-Head Attention
Multi-head attention allows the model to focus on different parts of the input simultaneously. Imagine you’re watching a movie while also reading subtitles and listening to background music. Your attention is divided into multiple ‘heads,’ each focusing on a different aspect. Multi-head attention does something similar.
Practical Applications
Natural Language Processing
Transformers have become the backbone of many NLP applications, from chatbots to sentiment analysis tools. Their ability to understand context makes them incredibly versatile.
Machine Translation
Ever wondered how Google Translate has become so accurate? It’s the Transformer architecture that’s doing the heavy lifting, enabling more accurate and context-aware translations.
Advantages Over Traditional Models
Efficiency
Transformers have redefined efficiency in natural language processing (NLP) and beyond. Unlike traditional models that process text sequentially, Transformers are parallelizable. This means they can simultaneously process all words or symbols in a sequence, significantly speeding up computations. This parallelization makes them highly efficient, reducing the time required for tasks such as language translation, sentiment analysis, and text summarization.
Scalability
The architecture of Transformers is designed to handle a wide variety of tasks, making them versatile and scalable. Whether you’re working with small text inputs or massive datasets, Transformers can adapt. They scale gracefully with both data size and task complexity, making them a top choice for large-scale applications like language translation, chatbots, and recommendation systems.
Challenges and Limitations
Computational Costs
While Transformers offer impressive capabilities, they come at a cost—computational power. Training these models demands substantial computing resources, which can be a hurdle for small organizations or individuals with limited access to high-performance hardware. This challenge has led to ongoing efforts to create smaller, more efficient versions of Transformers.
Ethical Considerations
Transformers, like all machine learning models, are trained on data collected from the internet, which may contain biases. As a result, these models can inherit and propagate these biases, potentially leading to unfair or biased outcomes in applications. Researchers and developers are actively addressing this issue by implementing fairness and bias mitigation techniques to ensure that Transformers provide equitable results.
Getting Started with Transformers
Tools and Libraries
To get started with Transformers, you can take advantage of popular machine learning libraries like TensorFlow and PyTorch. These libraries offer pre-built Transformer models and easy-to-use APIs, making it more accessible for newcomers to the field. This lowers the entry barrier and allows developers and researchers to experiment with Transformers without the need to build models from scratch.
Best Practices
When venturing into the world of Transformers, it’s advisable to start with smaller models and gradually progress to larger ones. Understanding the capabilities and limitations of each model is crucial for selecting the right one for your specific task. Additionally, keeping a watchful eye on the ethical implications of the data you use and the models you train is essential for responsible AI development.
Conclusion
Transformers have indeed revolutionized the field of machine learning and natural language processing. Their efficiency and scalability have paved the way for transformative applications across various industries. Whether you’re a seasoned AI practitioner or simply interested in the future of AI and machine learning, gaining a deeper understanding of Transformers is a valuable investment. With their increasing availability, continual research, and responsible usage, Transformers are shaping the landscape of AI, promising a future where machines understand and process human language and information with unprecedented accuracy and efficiency
FAQs
- What is the Transformer architecture? The Transformer architecture represents a groundbreaking development in machine learning, primarily designed for natural language processing tasks. It introduces a novel approach to processing sequential data that has significantly outperformed traditional models in various applications. Unlike previous models that relied on recurrent or convolutional layers to process sequences, Transformers employ a self-attention mechanism that enables them to capture complex relationships between elements in a sequence efficiently.
- Why are Transformers better than RNNs or CNNs? Transformers have gained prominence due to their superior efficiency and scalability, especially when dealing with sequence-to-sequence tasks. While recurrent neural networks (RNNs) and convolutional neural networks (CNNs) have been widely used for sequence processing, they face challenges in handling long sequences and capturing global dependencies. Transformers excel in these aspects by employing parallelization and self-attention mechanisms, enabling them to process sequences of varying lengths and capture long-range dependencies effectively. This makes them a preferred choice for a wide range of natural language processing tasks, including machine translation, text generation, and sentiment analysis.
- Are Transformers resource-intensive? Yes, Transformers are known to be resource-intensive, particularly during the training phase. Training large Transformer models with vast amounts of data requires substantial computational power and memory. This resource demand has sometimes been a barrier for smaller organizations or individuals with limited access to high-performance computing infrastructure. Researchers and engineers have been working on optimizing and compressing Transformer models to make them more accessible and efficient.
- What are the ethical considerations? One of the critical ethical considerations when working with Transformers is the potential for these models to inherit biases from the training data. Since Transformers are trained on data collected from the internet, which may contain biases related to gender, race, and other societal factors, the resulting models can unintentionally perpetuate these biases. Addressing bias in AI models, including Transformers, is an ongoing area of research and development. It involves techniques such as bias detection, data preprocessing, and fairness-aware training to ensure that AI systems provide equitable results and do not reinforce harmful stereotypes.
- How can I get started with Transformers? Getting started with Transformers is becoming increasingly accessible, thanks to the availability of libraries like TensorFlow and PyTorch. These libraries offer pre-built Transformer models and user-friendly APIs, making it easier for both newcomers and experienced practitioners to work with Transformers. You can start by exploring the documentation and tutorials provided by these libraries, gradually gaining hands-on experience with Transformer-based models. Additionally, it’s essential to keep abreast of the latest research and best practices in the field to make the most of Transformers in your machine learning and natural language processing projects.
If you want to learn more about statistical analysis, including central tendency measures, check out our comprehensiv PYTHON course. Our course provides a hands-on learning experience that covers all the essential statistical concepts and tools, empowering you to analyze complex data with confidence. With practical examples and interactive exercises, you’ll gain the skills you need to succeed in your statistical analysis endeavors. Enroll now and take your statistical knowledge to the next level!
If you’re looking to jumpstart your career as a data analyst, consider enrolling in our comprehensive Data Analyst Bootcamp with Internship program. Our program provides you with the skills and experience necessary to succeed in today’s data-driven world. You’ll learn the fundamentals of statistical analysis, as well as how to use tools such as SQL, Python, Excel, and PowerBI to analyze and visualize data designed by Mohammad Arshad, 18 years of Data Science & AI Experience. But that’s not all – our program also includes a 3-month internship with us where you can showcase your Capstone Project.
Are you passionate about AI and Data Science? Looking to connect with like-minded individuals, learn new concepts, and apply them in real-world situations? Join our growing AI community today! We provide a platform where you can engage in insightful discussions, share resources, collaborate on projects, and learn from experts in the field.
Don’t miss out on this opportunity to broaden your horizons and sharpen your skills. Visit https://nas.io/artificialintelligence and be part of our AI community. We can’t wait to see what you’ll bring to the table. Let’s shape the future of AI together!

Yeah bookmaking this wasn’t a high risk determination outstanding post! .