Python is a versatile programming language that is widely used by developers around the world. One of the key features that make Python a popular choice is its support for various data structures. These data structures play a vital role in programming and allow developers to organize and manipulate data efficiently. In this article, we will explore the different types of data structures in Python and how they can be used to solve complex problems.
1. Introduction
Python offers a wide range of data structures, each with its unique capabilities and advantages. These data structures are designed to handle different types of data, from simple numbers and strings to complex objects and collections. Understanding these data structures is crucial for writing efficient and effective Python programs.
In this article, we will explore the most commonly used data structures in Python, including lists, tuples, sets, dictionaries, arrays, queues, stacks, trees, and graphs. We will discuss the features and benefits of each data structure, as well as their applications in various programming scenarios.

2. Lists
Lists are the most commonly used data structure in Python. A list is a collection of elements that are ordered and mutable. This means that you can add, remove, or modify elements in a list as needed. Lists can contain elements of any data type, including numbers, strings, and even other lists.
Lists are often used to store and manipulate data in various programming scenarios. For example, you can use a list to store a collection of numbers or strings, or to represent a deck of cards in a card game. Lists are also used extensively in data science applications to store and manipulate large datasets.
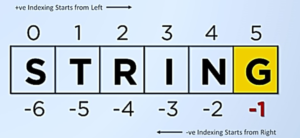
3. Tuples
Tuples are similar to lists, but they are immutable. This means that once you create a tuple, you cannot modify it. Tuples are often used to store and manipulate related data, such as the coordinates of a point in a graph or the dimensions of an image.
Tuples can be used as keys in dictionaries, making them a useful tool in data analysis and other programming scenarios. Tuples are also used extensively in functional programming, where immutability is a key feature.
A real-life application of tuples that comes to mind is in the field of geographical data handling.
Consider a situation where a mapping application is tasked with storing the locations of various landmarks. Each of these landmarks can be efficiently represented using a tuple that includes its name, latitude, and longitude coordinates.
For instance, the Eiffel Tower could be denoted by the tuple (“Eiffel Tower”, 48.8584, 2.2945). This tuple is composed of heterogeneous data types: a string representing the name of the landmark and two floating-point numbers for the geographic coordinates.
The tuple in this context serves two essential functions:
Heterogeneity: It combines different types of data – a string for the name and floats for the geographic coordinates – within a single structure. This is crucial in geographical applications, where complex information needs to be aggregated concisely and coherently.
Immutability: The tuple’s content, once set, cannot be changed. This attribute is particularly valuable for geographical data, where precision and consistency in the location coordinates are imperative. The immutability of tuples ensures the integrity of the data, safeguarding against unintended modifications.
This example of using tuples to represent geographical landmarks is a testament to their utility in managing and protecting complex and interrelated data, showcasing their practicality in real-world applications.
4. Sets
Sets are another data structure in Python that are used to store a collection of elements. However, sets are unordered and do not allow duplicate elements. This makes sets useful in situations where you need to store unique elements and perform set operations, such as union, intersection, and difference.
Sets are often used in data analysis and machine learning applications to store and manipulate datasets. Sets are also useful for removing duplicates from a list or other collection of elements.
5. Dictionaries
Dictionaries are a data structure in Python that allows you to store and retrieve data using key-value pairs. Dictionaries are unordered and mutable, which means that you can add, remove, or modify elements in a dictionary as needed.
Dictionaries are often used to store and manipulate data in various programming scenarios. For example, you can use a dictionary to store the contact information of people in an address book, or to represent a graph in a graph theory application.
6. Arrays
Arrays are a data structure in Python that allow you to store a collection of elements of the same data type. Arrays are often used in scientific and engineering applications to store and manipulate large datasets.
Arrays are more efficient than lists for storing and manipulating large datasets because they use less memory and support vectorized operations. Arrays can also be used in machine learning and data
processing applications to store and manipulate large matrices and vectors.
7. Queues
Queues are a data structure in Python that allow you to add elements to one end and remove them from the other end. Queues follow the “first-in, first-out” (FIFO) principle, which means that the first element added to the queue is the first one to be removed.
Queues are often used in various programming scenarios, such as job scheduling, network traffic management, and message passing systems. Queues can be implemented using lists or arrays, but Python provides a built-in Queue module that simplifies the process of working with queues.
8. Stacks
Stacks are another data structure in Python that follow a “last-in, first-out” (LIFO) principle. This means that the last element added to the stack is the first one to be removed. Stacks are often used in various programming scenarios, such as expression evaluation, function calling, and memory management.
Python provides a built-in stack module that makes it easy to work with stacks. You can also implement a stack using a list, but the stack module provides additional functionality, such as checking the size of the stack and clearing it.
9. Trees
Trees are a hierarchical data structure in Python that consist of nodes and edges. Each node in a tree can have zero or more children, and each child can have zero or more children, forming a tree-like structure. Trees are often used in various programming scenarios, such as file systems, search algorithms, and game theory.
Python provides a built-in tree module called “heapq”, which allows you to create and manipulate heaps, which are a special type of tree. You can also implement a tree using classes and objects in Python.
10. Graphs
Graphs are another type of data structure in Python that consist of nodes and edges, similar to trees. However, in a graph, each node can have zero or more edges, forming a more complex network structure. Graphs are often used in various programming scenarios, such as social networks, transportation networks, and network optimization.
Python provides a built-in graph module called “networkx”, which allows you to create and manipulate graphs. You can also implement a graph using classes and objects in Python.
11. Conclusion
Python offers a wide range of data structures that allow developers to organize and manipulate data efficiently. Each data structure has its unique features and advantages, and understanding them is crucial for writing efficient and effective Python programs. In this article, we have explored the most commonly used data structures in Python, including lists, tuples, sets, dictionaries, arrays, queues, stacks, trees, and graphs.
Whether you are working on a simple program or a complex data analysis project, knowing which data structure to use can make a significant difference in performance and efficiency.
Ready to level up your data skills? Enroll in our Basic Python course today and gain the knowledge and expertise needed to do Data projects with confidence. Start your learning journey now!
If you’re looking to jumpstart your career as a data analyst, consider enrolling in our comprehensive Data Analyst Bootcamp with Internship program. Our program provides you with the skills and experience necessary to succeed in today’s data-driven world. You’ll learn the fundamentals of statistical analysis, as well as how to use tools such as SQL, Python, Excel, and PowerBI to analyze and visualize data designed by Mohammad Arshad, 19 years of Data Science & AI Experience. But that’s not all – our program also includes a 3-month internship with us where you can showcase your Capstone Project.
Are you passionate about AI and Data Science? Looking to connect with like-minded individuals, learn new concepts, and apply them in real-world situations? Join our growing AI community today! We provide a platform where you can engage in insightful discussions, share resources, collaborate on projects, and learn from experts in the field.
Don’t miss out on this opportunity to broaden your horizons and sharpen your skills. Visit https://nas.io/artificialintelligence and be part of our AI community. We can’t wait to see what you’ll bring to the table. Let’s shape the future of AI together!

Some really superb information, Gladiolus I detected this.
excellent post, very informative. I wonder why the other specialists of this sector don’t notice this. You must continue your writing. I am confident, you’ve a great readers’ base already!
Hi there! This post couldn’t be written any better! Reading through this post reminds me of my previous room mate! He always kept talking about this. I will forward this article to him. Pretty sure he will have a good read. Thank you for sharing!
I don’t even know how I ended up here, but I thought this post was good. I don’t know who you are but definitely you’re going to a famous blogger if you aren’t already 😉 Cheers!
I was looking at some of your content on this internet site and I believe this internet site is very informative! Keep on posting.
I went over this web site and I think you have a lot of excellent information, bookmarked (:.
Thanks a bunch for sharing this with all of us you actually know what you are talking about! Bookmarked. Please also visit my site =). We could have a link exchange arrangement between us!
Would you be all in favour of exchanging links?
Does your blog have a contact page? I’m having a tough time locating it but, I’d like to shoot you an email. I’ve got some creative ideas for your blog you might be interested in hearing. Either way, great site and I look forward to seeing it improve over time.
I am glad to be one of many visitors on this outstanding internet site (:, appreciate it for putting up.
Loving the info on this internet site, you have done outstanding job on the posts.