Outline of the Article
- Introduction
- Overview of Pandas in Data Science
- Understanding Pandas
- Definition and Importance
- Installation and Setup
- Step-by-Step Guide
- Core Concepts
- Series and DataFrames Explained
- Basic Data Manipulation
- Sorting, Filtering, Indexing
- Data Analysis Techniques
- Statistical Methods in Pandas
- Data Visualization
- Integration with Matplotlib and Seaborn
- Handling Time Series Data
- Time-Based Data Features
- Machine Learning Data Preparation
- Using Pandas for ML Datasets
- Advanced Pandas Features
- Multi-Indexing and Pivot Tables
- Performance Optimization
- Techniques for Efficient Data Handling
- Learning Resources
- Books, Online Courses, Communities
- Common Challenges
- Solutions to Frequent Issues
- The Future of Pandas
- Upcoming Features and Developments
- Conclusion
- Recap and Final Thoughts
Introduction
Pandas, an open-source Python library, is pivotal in data science for data manipulation and analysis. It’s renowned for its ease of use, flexibility, and robust features that cater to a wide range of data operations.
Understanding Pandas
Pandas simplifies the process of data cleaning, transformation, and analysis. It’s designed to work with structured data, like tables, similarly to SQL or Excel, but with the power of Python.
Installation and Setup
Getting started with Pandas is straightforward. It can be installed via pip:
pip install pandas
Once installed, you can import it in your Python script:
import pandas as pd
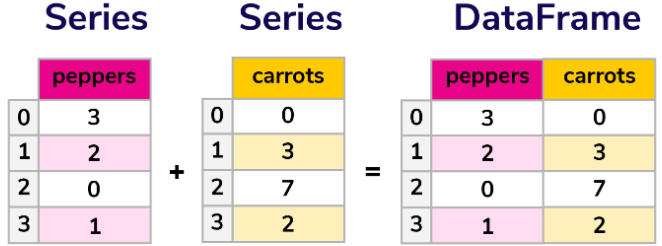
Core Concept
At the heart of Pandas are two primary data structures: Series and DataFrames. Series are one-dimensional arrays, while DataFrames are two-dimensional, resembling a table.
Basic Data Manipulation
Pandas excels in basic data operations. For example, to sort a DataFrame:
Mastering Pandas in Data Science
df.sort_values(by='column_name')
Filtering data:
df[df['column_name'] > value]
And indexing:
df.loc[row_indexer, column_indexer]
Data Analysis Techniques
Pandas offers a suite of statistical methods for data analysis. You can easily compute descriptive statistics:
df.describe()
Data Visualization
Pandas seamlessly integrates with Matplotlib and Seaborn for data visualization. To plot data:
df.plot(kind='bar')
Handling Time Series Data
Pandas is particularly strong in handling time series data, offering functionalities like resampling:
df.resample('M').mean()
Machine Learning Data Preparation
Pandas is an essential tool in the machine learning (ML) pipeline, primarily used for data preparation. This preparation involves several critical tasks, each contributing to the effectiveness of ML models.
- Handling Missing Data:
- Pandas offers various methods to deal with missing data, crucial for maintaining the quality of ML models. The
.fillna()method, for instance, allows you to replace missing values with a specified number or strategy, such as the mean or median of the column.
- Pandas offers various methods to deal with missing data, crucial for maintaining the quality of ML models. The
- Encoding Categorical Data:
- ML algorithms typically require numerical input, so categorical data must be converted. Pandas facilitates this through functions like
pd.get_dummies(), which converts categorical variable(s) into dummy/indicator variables.
- ML algorithms typically require numerical input, so categorical data must be converted. Pandas facilitates this through functions like
- Data Normalization:
- Normalizing data is another vital step. Pandas allows for easy integration with Scikit-Learn’s preprocessing tools, like
MinMaxScalerorStandardScaler, to scale numerical data.
- Normalizing data is another vital step. Pandas allows for easy integration with Scikit-Learn’s preprocessing tools, like
- Feature Selection:
- Selecting the right features is crucial. Pandas helps in feature engineering by providing functions for creating new features and dropping irrelevant ones.
Advanced Pandas Features
Mastering Pandas in Data Science
Advanced features in Pandas extend its functionality, enabling more sophisticated data operations.
- Multi-Indexing:
- Multi-indexing or hierarchical indexing allows you to have multiple index levels on an axis. This is particularly useful for working with high-dimensional data, enabling more refined data organization and manipulation.
- Pivot Tables:
- Pivot tables in Pandas are used for data summarization, a handy feature for quick data analysis and cross-tabulation. They provide an Excel-like pivot table functionality, making it easier to understand the relation between two or more features.
Performance Optimization
Mastering Pandas in Data Science
Optimizing data processing in Pandas is crucial for handling larger datasets more efficiently.
- Vectorization:
- Vectorized operations in Pandas are key to efficiency. These operations are performed on entire arrays instead of individual elements, significantly speeding up computations.
- Efficient Data Types:
- Choosing the right data type, like
categoryfor categorical data instead ofobject, can significantly reduce memory usage and improve performance.
- Choosing the right data type, like
- Chunking Large Data:
- For very large datasets, processing data in smaller chunks can be more feasible. Pandas allows for chunkwise processing which is less memory-intensive.
Learning Resources
Mastering Pandas in Data Science
A myriad of resources are available for learning Pandas, catering to various learning styles and levels.
- Books:
- “Python for Data Analysis” by Wes McKinney, the creator of Pandas, is a comprehensive resource covering fundamental and advanced aspects of Pandas.
- Online Courses and Tutorials:
- Platforms like Coursera, Udemy, and DataCamp offer structured courses, while YouTube and blogs provide more informal learning paths.
- Community Forums:
- Communities like Stack Overflow and the Pandas mailing list are invaluable for solving specific issues and staying updated with the latest trends and best practices.
Common Challenges Handling large datasets and complex data transformations are common challenges faced by Pandas users.
- Memory Usage:
- Pandas can be memory-intensive, making it challenging to work with very large datasets. Optimizing data types and using efficient coding practices can help mitigate this issue.
- Complex Data Transformations:
- Complex transformations might require deep understanding and advanced usage of Pandas functionalities, which can be daunting for beginners.
The Future of Pandas The future of Pandas is bright, with ongoing development to enhance its capabilities and performance.
- Continuous Updates:
- Regular updates are made to the library, introducing new features and improvements in performance.
- Community-Driven Development:
- Being open-source, Pandas benefits from a large community of contributors, ensuring its evolution aligns with the needs of its users.
Conclusion
Pandas is a cornerstone in the field of data science, offering a blend of simplicity and power. It simplifies data manipulation and analysis, making it an indispensable tool for data scientists. As the field of data science evolves, so does Pandas, continuously adapting and improving to meet the changing demands of data analysis and machine learning.
FAQs
- How does Pandas compare to other data manipulation tools?
- Pandas is more flexible and powerful than traditional tools like Excel, especially for large datasets and complex operations.
- Can Pandas handle big data efficiently?
- While Pandas is not designed for extremely large datasets, it can handle moderately large data efficiently, especially with optimization techniques.
- Is Pandas suitable for beginners in data science?
- Yes, Pandas is beginner-friendly and a great starting point for learning data manipulation and analysis.
-
- How is Pandas integrated with other Python libraries for data science?
- Pandas works seamlessly with libraries like NumPy, Matplotlib, and Scikit-Learn, forming a robust toolkit for any data science project. It’s particularly effective when combined with these libraries, enhancing its capabilities in data manipulation, visualization, and machine learning.
- What are the best practices for using Pandas in a data science team?
- Effective use of Pandas in a team setting involves consistent coding standards, adequate documentation, and leveraging its features to optimize data processing. It’s also crucial to stay updated with the latest Pandas developments and community best practices.
- How is Pandas integrated with other Python libraries for data science?
If you want to learn more about statistical analysis, including central tendency measures, check out our comprehensive PYTHON course. Our course provides a hands-on learning experience that covers all the essential statistical concepts and tools, empowering you to analyze complex data with confidence. With practical examples and interactive exercises, you’ll gain the skills you need to succeed in your statistical analysis endeavors. Enroll now and take your statistical knowledge to the next level!
If you’re looking to jumpstart your career as a data analyst, consider enrolling in our comprehensive Data Analyst Bootcamp with Internship program. Our program provides you with the skills and experience necessary to succeed in today’s data-driven world. You’ll learn the fundamentals of statistical analysis, as well as how to use tools such as SQL, Python, Excel, and PowerBI to analyze and visualize data designed by Mohammad Arshad, 18 years of Data Science & AI Experience. But that’s not all – our program also includes a 3-month internship with us where you can showcase your Capstone Project.
Are you passionate about AI and Data Science? Looking to connect with like-minded individuals, learn new concepts, and apply them in real-world situations? Join our growing AI community today! We provide a platform where you can engage in insightful discussions, share resources, collaborate on projects, and learn from experts in the field.
Don’t miss out on this opportunity to broaden your horizons and sharpen your skills. Visit https://nas.io/artificialintelligence and be part of our AI community. We can’t wait to see what you’ll bring to the table. Let’s shape the future of AI together!

It’s truly a nice and helpful piece of information. I’m glad that you shared this useful info with us. Please keep us informed like this. Thanks for sharing.