In the ever-evolving field of data science and artificial intelligence, the advent of Large Language Models (LLMs) has revolutionized how we extract information from documents. However, there has always been a challenge when it comes to processing images, which often contain crucial information not easily extractable by text-based LLMs. In this blog post, we’ll explore the exciting realm of multi-modal RAG (Retrieval-Augmented Generation) pipelines using Langchain, Gemini Pro models, and Chroma vector databases.
Learning Objectives
Before diving into the details, let’s set clear learning objectives for this journey:
- Understand the fundamentals of Langchain and Vector Databases.
- Explore different approaches to building multi-modal RAG pipelines.
- Learn how to create a multi-vector retriever in Langchain using Chroma.
- Build a complete RAG pipeline for multi-modal data.
Langchain and Vector Databases
Langchain emerges as a star player in the tech scene of 2023. It’s an open-source framework designed for building chains of tasks and LLM agents. Langchain comes equipped with a wide array of tools, ranging from data loaders to LLMs from various labs. Two key elements make Langchain stand out: Chains and Agents.
- Chains: These are sequences of Langchain components, where the outputs of one chain serve as the inputs for the next. To simplify development, Langchain offers an expression language called LCEL.
- Agents: Agents are autonomous bots powered by LLMs. They can adapt their actions based on data and descriptions of available tools.
For our multi-modal pipeline, we’ll utilize Langchain’s expression language and explore its potential.
Vector Databases, on the other hand, are purpose-built for storing embeddings of data. These databases are robust enough to handle millions of embeddings and are essential for context-aware retrieval. Embedding models are used to generate embeddings of data, typically trained on extensive datasets to measure the similarity of texts.
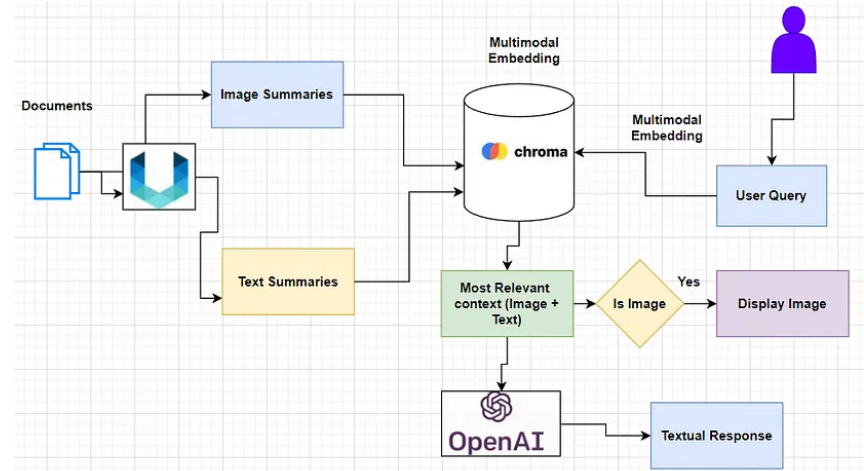
Approaches to Building Multi-Modal RAG Pipeline
Now, the question arises: How do we construct a RAG pipeline in a multi-modal context? Here are three distinct approaches:
Option 1: Use a multi-modal embedding model like CLIP or Imagebind to create embeddings of both images and texts. Retrieve them using similarity search and pass the documents to a multi-modal LLM.
Option 2: Employ a multi-modal model to generate summaries of images. Retrieve these summaries from vector stores and present them to an LLM for Question and Answering (Q&A).
Option 3: Utilize a multi-modal LLM to obtain descriptions of images. Embed these text descriptions using an embedding model of choice and store the original documents in a document store. Retrieve summaries with a reference to the original image and text chunks, then pass the original documents to a multi-modal LLM for answer generation.
Each of these options has its pros and cons. Option 1 is suitable for generic images but may struggle with complex charts and tables. Option 2 is a choice when multi-modal models can’t be used frequently. Option 3, with models like GPT-4V or Gemini, offers improved accuracy, especially for complex image understanding, but it comes at a higher cost.
In this article, we will implement the third approach, leveraging Gemini Pro Vision.

Building the RAG Pipeline
Now that we have a grasp of the concepts and tools involved, let’s outline the workflow for our multi-modal RAG pipeline:
- Extract images and texts from files.
- Obtain summaries of these images and texts using a vision LLM.
- Embed the summaries in Chroma vector databases and store the original files in an in-memory database.
- Create a multi-vector retriever that retrieves the original documents corresponding to their summaries using a similarity score.
- Pass the retrieved documents to a multi-modal LLM to generate answers.
Dependencies and Setup
To make this pipeline work seamlessly, we need to set up some dependencies, including Tesseract, Poppler, Unstructured, Langchain, Chroma, and more. These tools will help us handle different data formats, including images and texts, efficiently.
Image and Text Summaries
To generate concise summaries of our texts and images, we’ll use Gemini Pro. Langchain offers a summarizing chain for this purpose. We’ll use Langchain’s expression language to create a summarizing chain that can process texts and images effectively.
Multi-Vector Retriever
The heart of our multi-modal RAG pipeline is the multi-vector retriever. It stores embeddings of image and table descriptions in a vector store, along with the original documents in an in-memory document store. This allows us to retrieve the original documents corresponding to the retrieved vectors from the vector store.
RAG Pipeline
Finally, we’ll use the Langchain Expression Language to build the complete RAG pipeline. This involves chaining together various components, including the retriever, the question, the model, and the output parser. The RAG pipeline is responsible for taking a user query, retrieving relevant documents, and generating answers based on the context.
Conclusion
In the realm of data science and AI, multi-modal RAG pipelines have become indispensable tools for extracting information from a wide variety of data sources. They bridge the gap between text-based LLMs and the wealth of information present in images and other media.
In this article, we explored the powerful combination of Langchain, Chroma, Gemini, and Unstructured to build a multi-modal RAG pipeline. The key takeaways from our journey include:
- The significance of multi-modal RAG in augmenting existing RAG pipelines with LLMs capable of processing images.
- Understanding different approaches to building multi-modal RAG pipelines and choosing the one that suits your needs.
- The role of Langchain as an open-source framework for building LLM workflows and agents.
- The use of a multi-vector retriever to efficiently retrieve documents from multiple data stores.
As the field of AI continues to advance, multi-modal RAG pipelines are set to play a crucial role in unlocking insights from a wide range of data formats, making them an essential tool for data scientists and AI practitioners.
Frequently Asked Questions
Q1. What is Langchain used for? A. Langchain is an open-source framework that simplifies the creation of applications using large language models. It can be used for various tasks, including chatbots, document analysis, code analysis, question answering, and generative tasks.
Q2. What is the difference between chains and agents in Langchain? A. Chains are sequences of Langchain components, while agents are more complex and can make decisions based on data and descriptions of tools. Agents are often used for tasks that require creativity or reasoning, such as data analysis and code generation.